Data is the fuel for any machine learning model despite the type of learning algorithm (Gradient-based or tree-based) being used. To train and test the model’s generalization capacity, typically, we divide the available samples into three sets: Training, Validation and Test. The typical requirement is that the samples in the test set should be different from the training and validation sets. Well, this stringent (of course, valid) requirement could not be met in the case of training and testing LLMs.This is because the datasets are derived from the snapshots of Common Crawl Web! It is difficult to verify that the model has not seen the samples used by the benchmarking sets during training.
Moreover, the quality of the large language models benefits greatly from the size of the pretraining corpora as long as its quality is preserved. That requires one to build a data pipeline. Let us first look at the data sources available on the internet.
Data Sources
Fortunately, for the language modelling tasks, all we need is raw texts. One can get it directly from the internet.
Wikipedia
- As of today, it supports articles written in 326 active languages
- English Wikipedia contains about 59 million pages (top) Ref
- Hindi with 1.2 million pages
- Tamil language with 0.5 million pages
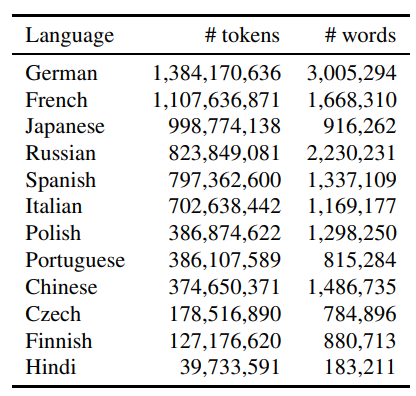
- The following table gives us a better summary of the number of tokens available in each language (as of 2018). The second column (#words) shows the words that occurred at least 5 times in the corpus.
-
Overall, 28 languages contain more than 100 million tokens, and 82 languages contain more than 10 million tokens Ref
-
Major Limitation: Wikipedia is a good source if you are focusing only on English. For languages like Tamil, we have only 0.5 million pages (low resource?). Therefore, one needs to search through the ocean of documents.
Common Crawl:
- Massive non-curated dataset of webpages in many languages, mixed together in temporal snapshots of the web
- Contains 250 Billion pages and 3 to 5 Billion pages are being added every month (by sampling the entire web).
- There is little content overlap between monthly snapshots
- Each snapshot is 20 to 30 TB in size (containing uncompressed text)
- Data comes in three formats: raw Web ARChive (WARC), UTF-8 Web Extracted Text (WET), meta-data (WAT)
Data Pipelines
Common Crawl takes snapshots of everything on the internet. Therefore, to derive a dataset (monolingual or multi-lingual) we have to deploy a pipeline to remove duplicates, bad words and identify the language in which the document is written. It is a highly complex and computationally intensive process that costs thousands of dollars. The processes in the pipeline are not standardized and therefore no pipeline is perfect!
In all these pipelines, some sort of language models (n-gram or small language models) are used to decide the quality of the page/article.
fastText
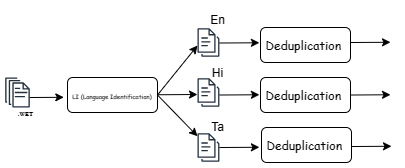
A simple pipeline proposed in the paper shown below contains language identification and deduplication (using hashing algorithms).
-
Note, however, that LI followed by deduplication or deduplication followed by LI has some impact on the quality of the filtered articles.
-
It uses line-level deduplication.
CCNet
- Describes an automatic data collection pipeline to extract massive high-quality monolingual datasets from Common Crawl for a variety of languages
- Follows standard language detection and deduplication process as in fastText
- However, it preserves document structure at the paragraph level (instead of line-level language detection as in [1])
- Adds an optional monolingual filtering step that selects documents that are close to high quality sources, like Wikipedia (using a language model to detect it)
- The pipeline is shown below (taken from the paper)
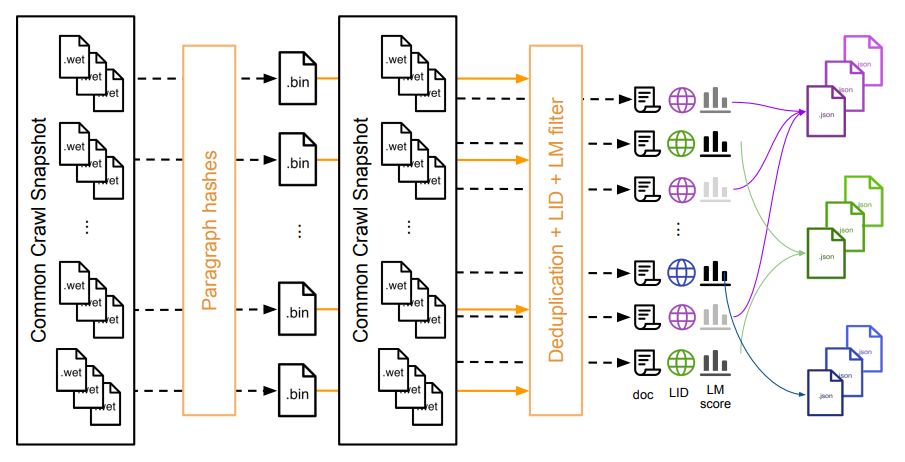
- The 25 TB of data is divided into 1600 shards each of size 5GB.
- Compute paragraph hashes from the raw .WET files (this will help remove many boilerplate codes in the deduplication step)
- These shards are saved into a JSON file where one entry corresponds to one web page.
- Note that the order of the process has been changed. Deduplication is the first step and then identifying language and applying LM filtering to extract articles from high-quality resources.
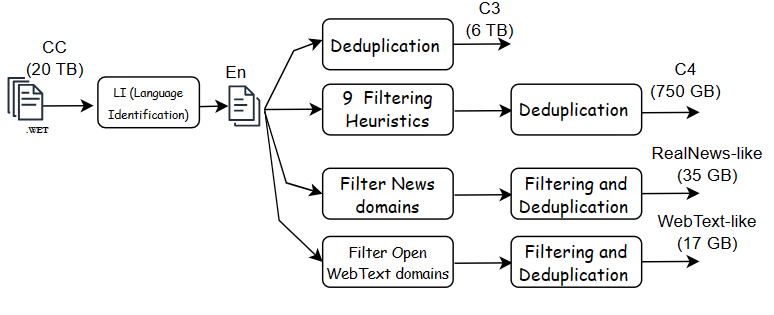
C4 Pipeline (360 Billion tokens)
- Apply aggressive filtering heuristics to produce a Colossal Clean Crawled Corpus (C4) of size 750 GB of natural language text.
- Derives the following datasets from the C4
- RealNews-like (35 GB)
- WebText-like 17 GB (Used Common Crawl Snapshots from Aug 2018 to Jun 2019)
- Unfiltered C4 (6.1 TB)
- The diagram below shows the data flow pipeline. You may take a look at the source code to get more details
-
In the subsequent work, the above pipeline is modified to include 100+ other languages by crawling 70+ months of crawl data (amounts to Petabytes of data). The new dataset is called mC4
-
For example, by using all these snapshots, the number of pages for Tamil language has increased to 3.5 million compared to 0.5 million pages (had we used Wikipedia alone)
-
Another contemporary multilingual dataset is OSCAR. However, it followed fastText pipeline and did not apply any filtering heuristics.
-
Limitation: C4 and mC4 applies aggressive filtering. Moreover, would it be helpful to consider WARC files from the common crawl to extract texts? How to make the data as diverse as possible?
The Pile (340 Billion tokens)
- Follows the same pipeline above but uses WARC format directly instead of WET format. Uses justText to extract text directly from WARC and pycld2 instead of fastText for language detection. Imposes stringent quality requirements. This results in 250 GB of English text.
- Uses Fuzzy deduplication
- Emphasizing on the quality and diversity, the dataset contains text from various sources as shown in the table below (taken from the paper)
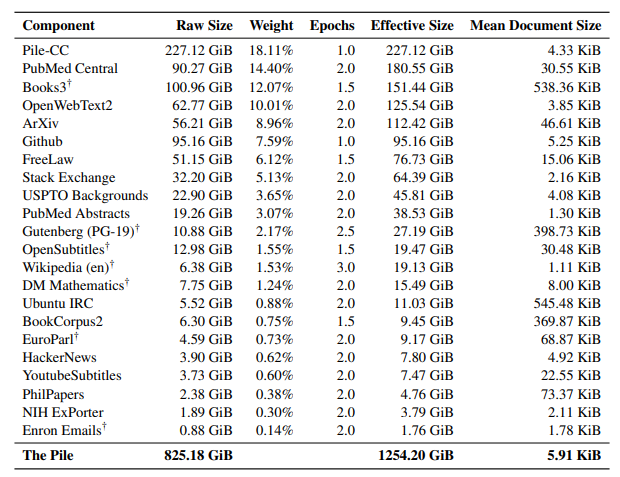
- For this reason it is called curated dataset
Refined-web (5 Trillion tokens)
- Once again, the quality of data matters! Extract directly from WARC
- Uses both exact and fuzzy deduplication
- Important: It uses data from the Web only (that is, extracted from CC ). Not from diverse sources as suggested in the pile.
End note
- The list is not exhaustive. I can quote a few more datasets, say RedPajama, MassiveWeb and so on. The underlying data pipeline of all large-scale datasets follows more or less the pipeline described in CCNet or fastText. The released datasets are either curated or derived from CC.
Questions to Ponder
- Will we run out of unique high-quality text data soon?
- How scalable is the curation?
- How good are these datasets? How do we measure? (one idea is to see the impact on zero-shot generalization of LLMs as mentioned in [6])
- How do we build a dataset for Indic languages? There are great open-source initiatives by AI4Bharat and other organizations.