GPT (Generative Pre-trained Transformer)
- Pre-training Dataset: Book corpus (0.8 Billion words)
- Unsupervised objective: CLM (Autoregressive)
- Tokenizer: Byte Pair Encoding (BPE)
- Vocab size: 40K
- Architecture: Decoder only (12 Layers)
- Activation: GELU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal Mask
- Positional Encoding: Absolute (learnable)
- Optimizer: Adam
- Training steps: 100 epochs ($2.4 \times 10^6$ steps), ($BS:64 \times T:512$) tokens/step
- Number of parameters: 0.12 Billion
- Evaluated on : 12 Tasks (includes NLI, QA, Comprehension, Classification)
BERT (Bidirectional Encoder Representation from Transformers)
- Pre-training Dataset: Book corpus (0.8B words), English Wikipedia (2.5B words)
- Unsupervised objective: MLM (Autoencoding)
- Tokenizer: WordPiece (similar to BPE)
- Vocab_size: 30K
- Architecture: Encoder only (12 Layers (BERT-base), 24 layers (BERT-large))
- Activation: GELU
- Attention: Dense
- FFN: Dense
- Attention mask: No Mask
- Positional Encoding: Absolute (learnable)
- Optimizer: Adam
- Training steps: 40 epochs ($1 \times 10^6$ steps), ($BS:256 \times T:512$) tokens/step
- Number of parameters: 0.12 Billion (Base) to 0.34 (Large)
- Evaluated on : 11 Tasks (includes NLI, QA, Comprehension, Classification)
BART (Bidirectional Autoregressive Training)
- Pre-training Dataset: Book corpus,English Wikipedia,CC News, Stories (total:160 GB of text data)
- Unsupervised objective: MLM (token masking, deletion, text infilling, sentence shuffling)
- Tokenizer: BPE
- Vocab_size: 50K
- Architecture: Encoder-Decoder (6-6 Layers (BART-base), 12-12 layers (BART-large))
- Activation: GELU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal mask in Decoder
- Positional Encoding: Absolute (Learneable)
- Optimizer: Adam
- Training steps: BERT-Like : 40 epochs ($1 \times 10^6$ steps), ($BS:256 \times T:512$) tokens/step
- Training steps: RoBERTa Like: $0.5 \times 10^6$ steps, ($BS:8000 \times T:512$) tokens/step
- Number of parameters: 0.13 Billion (Base) to 0.37 (Large)
- Evaluated on : 15 Tasks
T5 (Pushing the limits)
- Objective: Extensive study on existing approaches to building (Large) LMs under a unified (Text-To-Text-Transfer-Learning) framework.
- Pre-training Dataset: Colossal Clean Crawled Corpus C4 (156 Billion tokens)
- Unsupervised objective: MLM-Denoising (predicting a span of missing tokens)
- Tokenizer: Sentencepiece
- Vocab_size: 32K
- Architecture: Encoder-Decoder (tiny, small, medium, large)
- Activation: ReLU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal mask in Decoder
- Positional Encoding: Modified position encoding
- Optimizer: Adafactor
- Training steps: $<\frac{1}{4}$ of epoch ($2^{19}=524,288$ steps), ($BS:128 \times T:512=65536$) tokens/step
- Number of parameters: 0.13 Billion (small) to 11 Billion (Large)
- Evaluated on: 23 Tasks (GLUE, superGLUE, SQuAD, CNN/DM, WMT)
GPT-2
- Pre-training Dataset: Study zero-shot task transfer
- Pre-training Dataset: WebText (40 GB) (less than 19 Billion tokens)
- Unsupervised objective: CLM
- Tokenizer: Bytelevel BPE
- Vocab_size: 50K
- Architecture: Decoder (4 variants)
- Activation: GELU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal mask
- Positional Encoding: Absolute (learnable)
- Optimizer: Adam
- Training steps: not disclosed. Model underfits the dataset (similar to T5) ($BS:64 \times T:1024=65536$) tokens/step
- Number of parameters: 0.12 Billion (small) to 1.5 Billion (Large)
- Evaluated on: 8 Tasks
GPT-3
- Objective: Scaling parameters and improve zero-shot, few-shot performance
- Pre-training Dataset: (700 GB) 300 Billion tokens from weighted sampling (60% of Common Crawl filtered (410 B), 22% of WebText-2 (19 B),8% of Books 1(12 B),8% of Books 2 (55 B),2-3% of Wikipedia (3 B))
- Unsupervised objective: CLM
- Tokenizer: Bytelevel BPE
- Vocab_size: 50K
- Architecture: Decoder (12 layers to 96 layers)
- Activation: GELU
- Attention: Sparse Factorization
- FFN: Dense
- Attention mask: Causal
- Positional Encoding: Absolute (learnable)
- Optimizer: Adam
- Training steps: (Inferred) 1 epoch = 93570 steps with 3.2M batch size (tokens) ($\frac{300 \times 10^9}{3.2 \times 10^6}$), ($BS:0.5M \rightarrow 3.2M \tokens$). Total training steps could also be inferred from the total compute (PF-days) used to train the model.
- Number of parameters: 0.12 Billion (small) to 175 Billion (Large)
- Evaluated on: 28+ Tasks
- New finding: In-context learning
Switch (Scaling up T5 with MoE)
- Objective: Scale to Trillion parameters with a reduced computational budget (FLOPS/token)
- Baseline: T5 small (223M), T5 Large (739)
- Pre-training Dataset: Improved C4 (156 Billion tokens)
- Unsupervised objective: MLM-Denoising (predicting span of missing tokens)
- Tokenizer: Sentencepiece
- Vocab_size: 32K
- Architecture: Encoder-Decoder (tiny, small, medium, large)
- Activation: ReLU
- Attention: Dense
- FFN: Sparsely activated with MoE (Mixture of Experts) paradigm.
- Number of experts: 64 (base)
- Attention mask: Causal mask in Decoder
- Positional Encoding: Modified position encoding
- Optimizer: Adafactor
- Training steps: $<\frac{1}{4}$ of epoch ($2^{19}=524,288$ steps), ($BS:128 \times T:512=65536$) tokens/step
- Number of parameters: 7 Billion (base) to 1571 Billion (Switch-C)
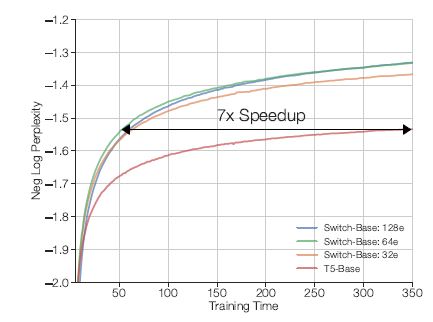
- Speed-up: 7.5x (switch base over dense T5 base), 2.5x (switch large over dense T5 large) Metric for comparison against T5 and MoE Transformers</span>: Constant FLOPS (T5 base (0.2B Parameters) and Switch base (7B parameters) have same FLOPS/Sequence)
- In the diagram below $e$ denotes the experts. For example, $64e$ means 64 experts. Note carefully that increasing experts beyond a point increases the communication cost and hence decreases speed-up.
GLM (Generalized Language Models - Unifying Framework)
- Objective: Pose all problems as text generation problem
- Pre-training Dataset: Book corpus, English Wikipedia, CC News-en, OpenWebText-2 (158GB total)
- Unsupervised objective: MLM-text-infilling
- Tokenizer: Sentencepiece
- Vocab_size: 30K
- Architecture: Encoder-Decoder (3 variants)
- Activation: GeLU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal mask in Decoder
- Positional Encoding: 2D positional encoding (i.e., instead of using different positional encoding each for encoder and decoder)
- Training steps: Same as BERT for comparison, half of RoBERTa and BART due to resource constraints.
Gopher (Deepmind)
- Objective: Scaling parameters and improve zero-shot, few-shot performance
- Pre-training Dataset: MassiveText (10TB, 2 Trillion tokens) (compiled from MassiveWeb, Books, C4, Github, Wikipedia), use 300 Billion tokens (12% of the total), evaluated on The pile (800GB)
- Unsupervised objective: CLM
- Tokenizer: Bytelevel BPE
- Vocab_size: 50K
- Architecture: Decoder (6 variants, 8 layers to 80 layers)
- Activation: GELU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal
- Floating point Precision: fp32,bfloat16
- Positional Encoding: Relative
- Optimizer: Adam (pre-training)/AdaFactor(fine-tuning)
- Number of parameters: 44 Million to 280 Billion
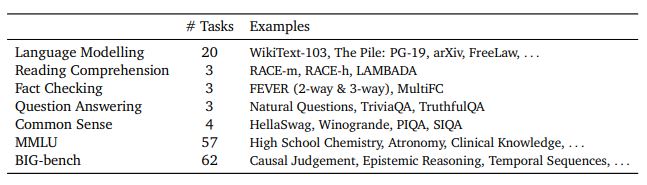
- Evaluated on: 120 tasks
InstructGPT (precursor to chatGPT)
-
Traditional approach: Train /finetune LMs (Meena (2B parameters, 40B tokens) and LaMDA (137B parameters, 1.4T tokens)) for chat applications on dialog datasets (like social media conversations) using LM objectives. The responses generated by them were unintended and toxic.
-
- Problem: Predicting the next token objective is different from following user instructions helpfully and safely.
-
Solution: Align the model objective to user intent with human feedback
-
Guiding principles: Helpful (solve the task)-Honest(do not fabricate or mislead)- Harmless(physical or psychological)
-
Pre-trained model: GPT-3
- Fine-tuning strategy: RLHF (Reinforcement Learning with Human Feedback) where human feedback acts as a reward signal (Supervised Fine Tuning - Reward Modelling - RLHF with PPO (Proximal Policy Optimization))
Chinchilla (Compute-Optimal Language Model)
- Objective : Find the optimal model size and number of tokens for training a transformer language model under a given compute budget (similar to power law)
- Core problem : Is the model size of Gopher optimal for the given compute budget ($10^{25}$ FLOPS)?
- Findings: Model size and data size scale equally (doubling the model size (parameters) requires us to double the data size (measured in tokens) to get improved performance) as shown in the figure below (last row)
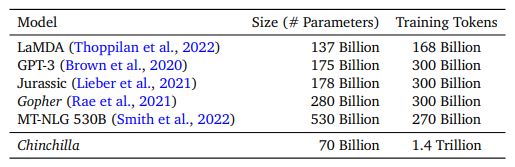
-
The optimal size of Gopher: According to the new law, the optimal model size (parameters) of Gopher (trained with 1.4 Trillion tokens) is not 280 Billion but 70 Billion.
-
The optimal size of GPT-3: According to the new law, the GPT-3 with 175 Billion parameters should have been trained on 4.2 Trillion tokens (for it to be optimal)
- Pre-training Dataset: MassiveText with a slight modification of weightage to account for 1.4 Trillion tokens
- Tokenizer: SentencePiece (to represent math and chemistry symbols)
- Vocab_size: 45K
- Architecture: Decoder (80 layers)
- Activation: GELU
- Attention: Dense
- FFN: Dense
- Attention mask: Causal
- Floating point Precision: fp32 (storage),bfloat16 (training)
- Positional Encoding: Relative
- Optimizer: AdamW
- Number of parameters: 70 Billion (optimized Gopher :-) )
PaLM (Pathways Language Model)
- Objective: Efficiently Scale the model to 540 Billion parameters using Pathways system.
- Pre-training Dataset: 780 Billion tokens (natural language, codes from 24 programming languages, social media conversations)
- Unsupervised objective: CLM
- Tokenizer: SentencePiece
- Vocab_size: 256K
- Architecture: Decoder (32, 64, 118 Layers)
- Activation: SwiGELU (SwishGELU)
- Attention: Multi-Query Attention (to improve decoding speed)
- FFN: Dense
- Attention mask: Causal
- Positional Encoding: RoPE (works better for long sequences)
- Normalization: Pre-Norm (RMSNorm)
- Optimizer: AdaFactor (without factorization).
- Training steps: 255k (BS: vary from 1M,2M and 4M tokens)
- Evaluated on: 120+ tasks (NLU, MMLU, BIG-Bench,..)
- Hardware: 6144 TPU v4 chips
- Parallelism: Data and Model Parallelism
LLaMA
- Motivation: In line with Chinchilla and scaling law, train a smaller model with Trillion tokens (longer time)
- Objective: Optimize the inference budget with smaller models (7B to 65B)
- Pre-training Dataset: Common Crawl (2017 to 2020), C4, Github, Arxiv, StackExchange
- Unsupervised objective: CLM
- Tokenizer: BPE
- Architecture: Decoder (32, 40, 60, 80 Layers)
- Activation: SwiGELU (SwishGELU)
- Attention: Flash Attention
- FFN: Dense
- Attention mask: Causal
- Positional Encoding: RoPE (works better for long sequences)
- Normalization: Pre-Norm (RMSNorm)
- Optimizer: AdamW.
- Training steps: 255k (BS: vary from 1M,2M and 4M tokens)
- Evaluated on: 120+ tasks (NLU, MMLU, BIG-Bench,..)
- Hardware: 2048 A100 GPUs (80GB RAM) (380 tokens/s/GPU)
- Parallelism: Data and Model Parallelism